
Olá, pessoal!
Voltando aos posts sobre VEEAM, hoje irei demonstrar como fazer um backup de uma VM Windows criando uma rotina de backups full e incremental. Com esse tipo de backup poderemos recuperar arquivos de forma granular pelo backup ou ainda fazer o download do VMDK, por exemplo.
Então, sem mais delongas, vamos ao passo a passo.
Antes de iniciar a criação do job precisamos criar o repositório do backup no VEEAM, que nada mais é do que o local que serão gravados nossos backups. Para isso, na console do VEEAM, devemos clicar em “Backup Infrastructure”:
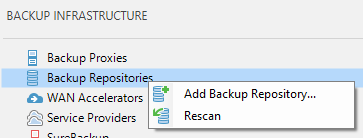
Clique em “Backup Repositories” e escolha a opção “Add Backup Repository…”
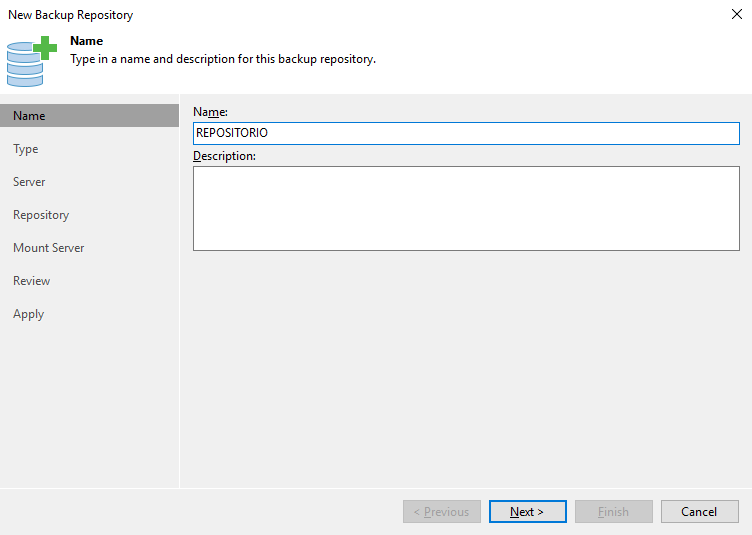
Será iniciado o wizard para criação do repositório. Defina um nome e descrição e clique em “Next”.
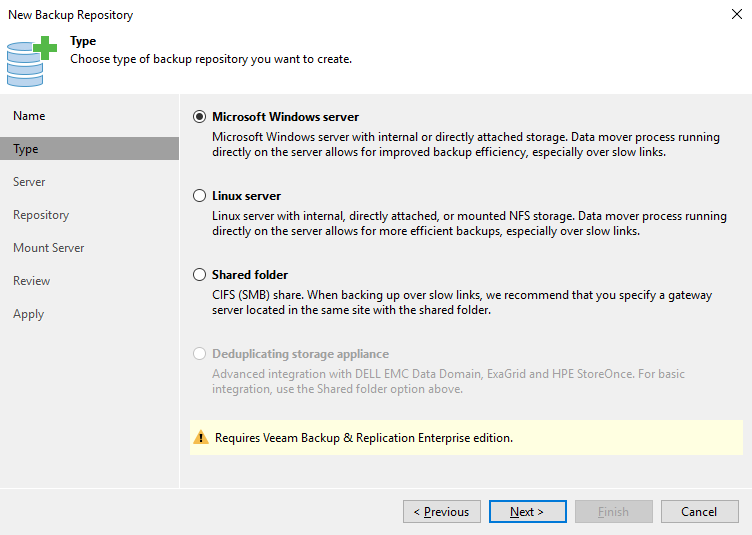
Em “Type” devemos escolher qual o tipo do nosso repositório. O VEEAM aceita alguns tipos:Em “Type” devemos escolher qual o tipo do nosso repositório. O VEEAM aceita alguns tipos:
- Microsoft Windows Server
- Como o próprio nome diz, nesse caso utilizaremos um servidor windows com discos locais ou uma storage plugada nesse servidor;
- Linux Server
- Mesmo caso que o Windows, só mudando o SO;
- Shared Folder
- Podemos utilizar uma pasta compartilhada com o protocolo SMB;
- Deduplicating storage appliance
- Podemos utilizar também alguns modelos de storages e já utilizar a deduplicação nativa desses devices, mas para isso é necessário a licença Enterprise do VEEAM;
Escolha a opção que mais se adeque ao seu ambiente e clique em “Next”. Nesse caso escolherei a opção “Microsoft Windows server”.
Na próxima tela devemos escolher o servidor que será o repositório. No meu caso, o meu repositório ficará localizado no próprio servidor de VEEAM, mas você pode clicar em “Add New” e adicionar um outro servidor. Você também pode clicar em “Populate” para mostrar os “Paths” disponíveis no servidor, mas esse passo não é obrigatório. Clique em “Next” para prosseguir.
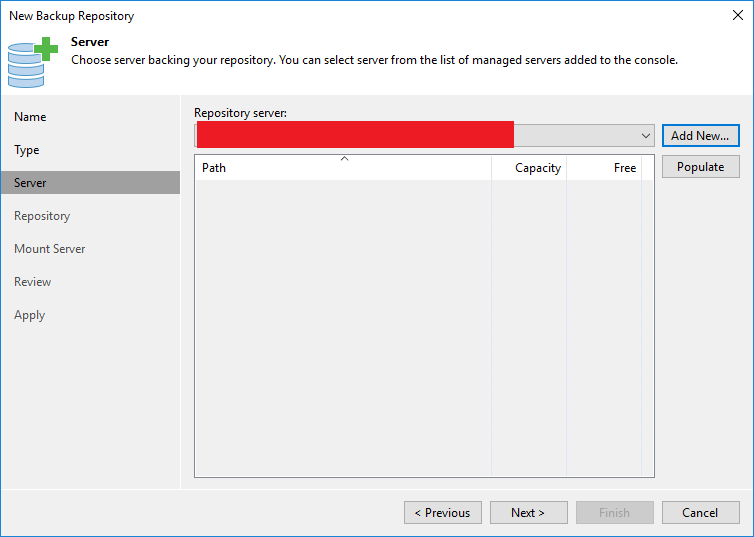
Na próxima tela vamos configurar algumas opções do repositório. Em “Path to Folder” vamos selecionar a pasta onde o backup será gravado. Clique em “Browser”.
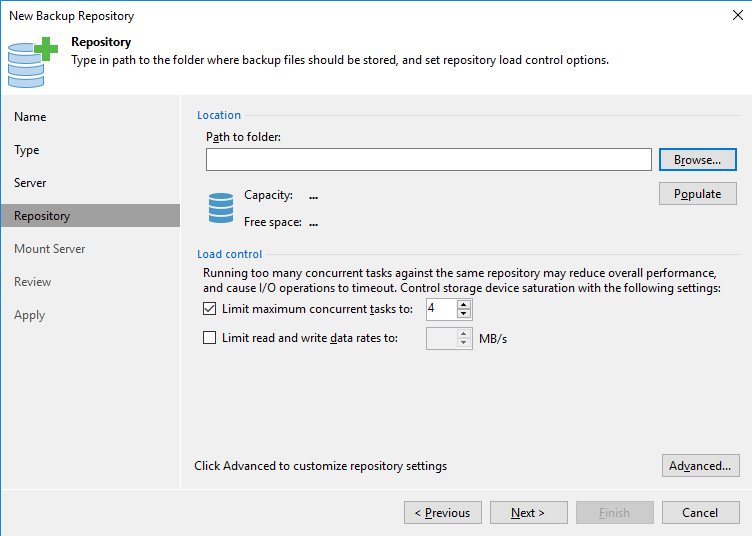
Selecione a pasta que deseja que o backup seja gravado e clique em “OK”.
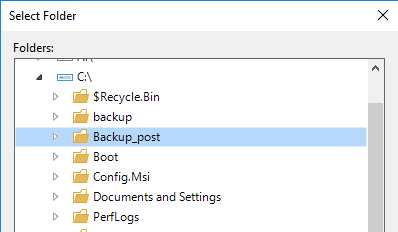
Em “Load Control” podemos limitar quantos jobs consecutivos pode ser rodado nesse repositório, além de definir a taxa de throughput. Dependendo do seu ambiente, pode ser algo útil, mas em geral eu não utilizo porque não costumo rodar vários jobs ao mesmo tempo no mesmo repositório.
Clicando em “Advanced” temos as seguintes opções de configuração:Clicando em “Advanced” temos as seguintes opções de configuração:
- Align backup file data blocks
- Utilizado para alinhar os blocos do backup em um storage para melhorar o a deduplicação, mas só é utilizado em casos de gravação dos dados em storage com suporte a esse recurso.
- Decompress backup data blocks before storing
- Outro recurso utilizado para casos que a deduplicação e a compressão de dados está ativada. Essa opção comprimi os dados na VM de origem, antes de trafegar os dados, depois disso trafega os dados comprimidos e no repositório ele é descomprimido para atingir uma maior taxa de deduplicação, já que deduplicar arquivos comprimidos não te dará tanto ganho. Novamente, use a opção somente em casos em que você está utilizando compressão e deduplicação.
- This repository is backed by rotated hard drives
- Quando rodamos um backup utilizando o VEEAM, inicialmente é criado o full e dependendo de como configurarmos o jobs teremos arquivos incrementais. Os arquivos possuem dependência um do outro para que você crie uma cadeia de arquivos e possa voltar em qualquer momento necessário. Com essa opção, pensando em uma rotina de rotação, o VEEAM irá tolerar o desaparecimento de arquivos de backup dos dias anteriores. Pode ser útil em caso de utilização de uma rotina de rotação de fitas, por exemplo.
- Use per-VM backup files
- Essa opção pode ser usada para ter múltiplos I/O streams para um storage que suporte essa função. Entretanto, só está disponível na versão Enterprise do VEEAM.
Para maiores informações sobre essas opções CLIQUE AQUI.
No caso do meu exemplo não usarei nenhuma dessas opções. Clique em “OK” e “Next” para a próxima tela.
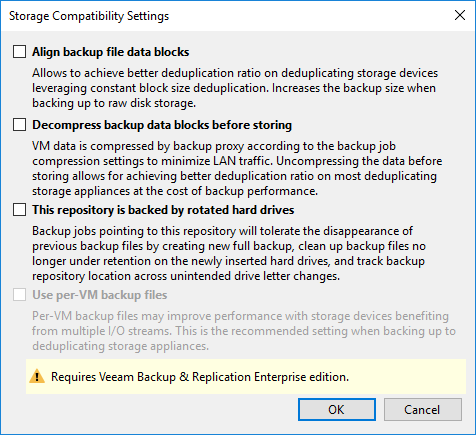
Quando vamos efetuar o restore de um backup o VEEAM precisa “montar” a VM para que você tenha todas as opções de restore disponível, como VM Recovery, SureBackup e File-Level Restore. Por isso, devemos definir qual será nosso “Mount Server”. Como nesse exemplo o meu repositório é meu próprio servidor, irei manter as configurações padrões.
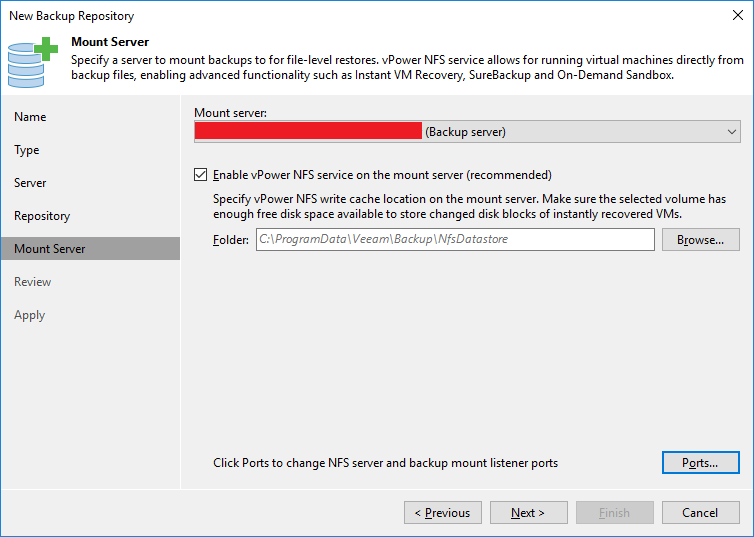
Clicando em “Ports” podemos mudar as portas de comunicação com o “Mount Server”.
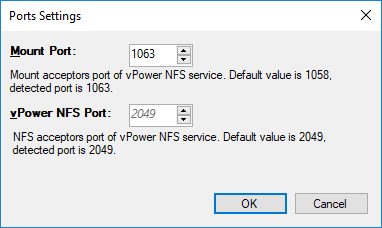
Para maiores detalhes sobre o Mount Server CLIQUE AQUI.
Clique em “OK” e “Next” para prosseguir.
Clique em “Apply” para iniciar a criação do repositório.
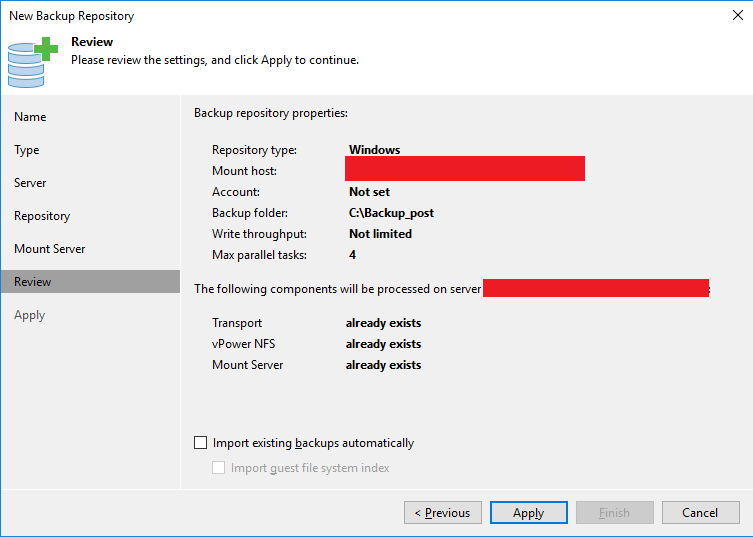
Clique em “Finish” para finalizar o processo.
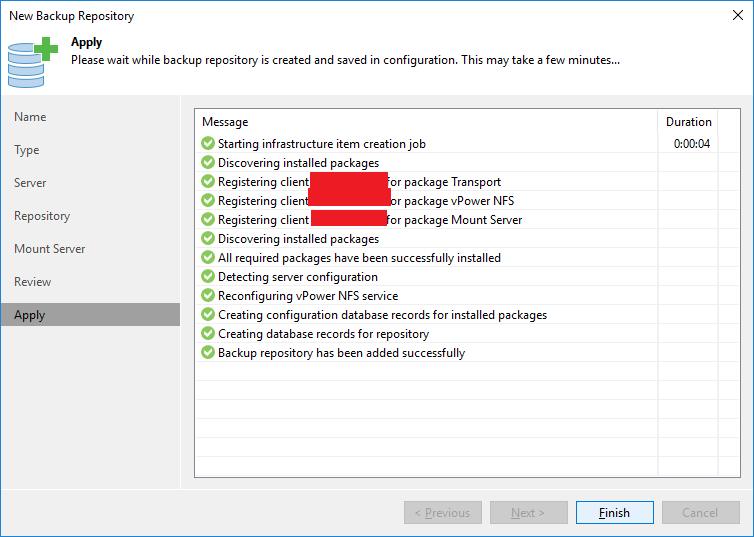
Agora com o repositório criado, vamos iniciar a criação do job de backup clicando em “Backup Job” na console.
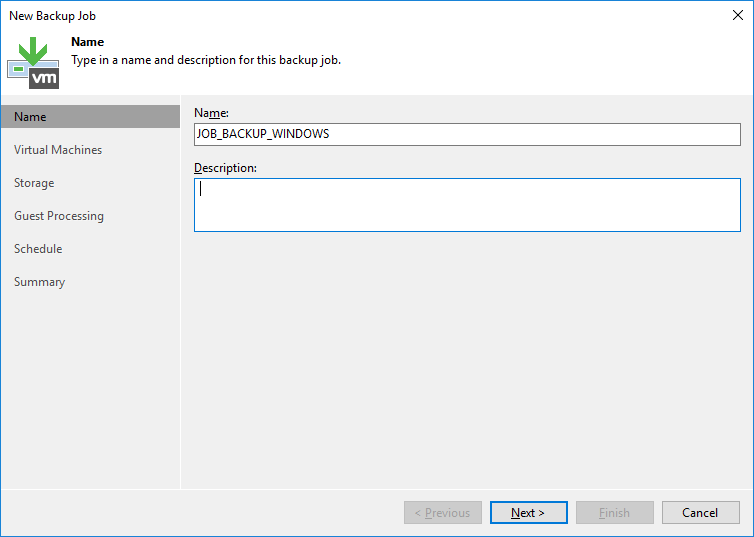
Será aberto o wizard para criação do Job de Backup. Defina um nome para o job e clique em “Next”.
Clique em “Add” para procurar a VM que deseja fazer o backup. Você também pode escolher um host inteiro e criar exclusões se necessário, assim como mostrei no artigo sobre replicação.
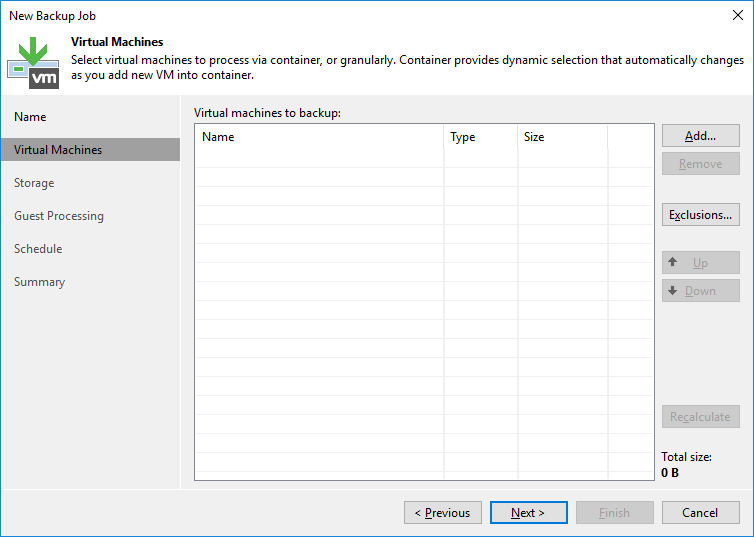
Irei escolher uma VM simples com Windows Server 2012 R2 para demonstrar o processo. Após escolher a VM clique em “OK”.
E depois clique em “Next” para prosseguir.
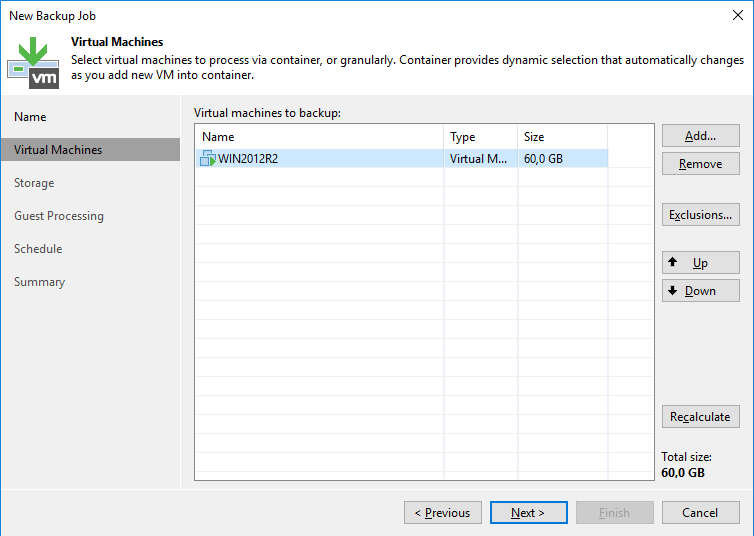
Na próxima tela primeiro devemos escolher nosso “Backup Proxy”. No meu caso esse servidor é o único de VEEAM que possuo, por isso deixarei em “Automatic Selection”, mas você pode definir outro servidor de proxy principalmente se estiver fazendo backup através de uma rede WAN onde a VM de origem está em outro site. Nesses casos é sempre importante fazer o deploy de um outro servidor de VEEAM nesse site para agir como proxy do backup porque ele está mais próximo logicamente da VM de origem e como isso teremos uma performance melhor do job.
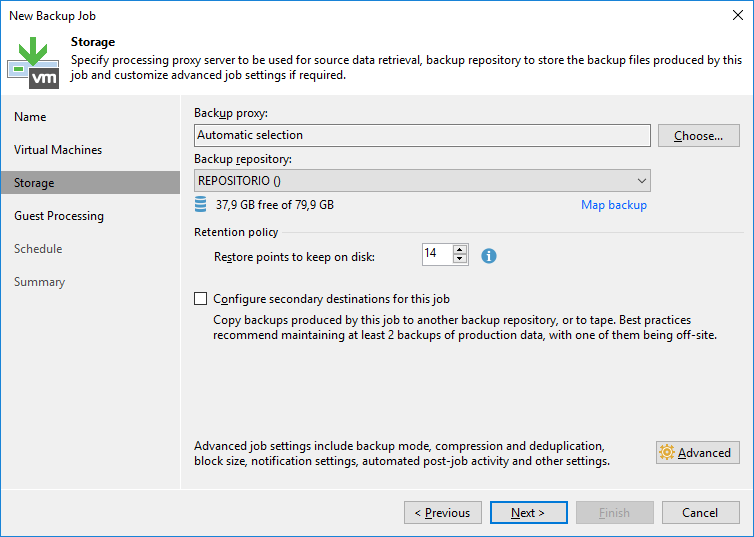
Em “Backup Repository” vamos escolher no repositório criado.

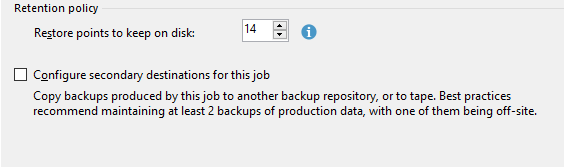
Em “Retetion Policy” podemos definir a política de retenção de quantos restore points você deseja manter. Por padrão vem marcado 14, mas você pode adequar da melhor para o seu ambiente.
Você também pode configurar um destino secundário para o backup, no caso de que você rode o seu backup e depois de finalizar precise copiar ele para um outro destino. Isso é feito utilizando um jobs de Backup Copy, como não é nosso caso manterei desmarcado.
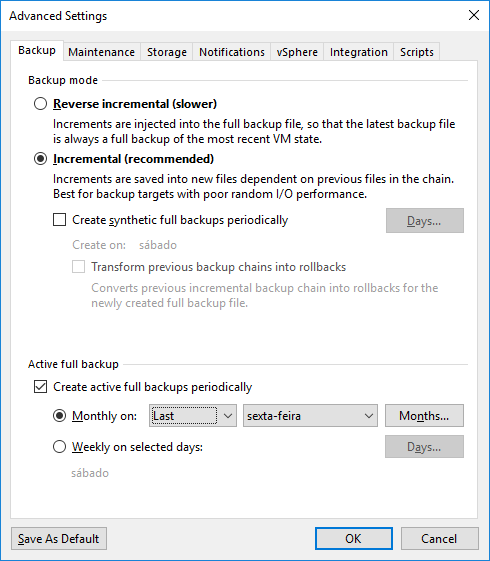
Clicando em Advanced teremos diversas opções de configuração. Na aba “Backup” podemos escolher qual o modo que nosso backup irá funcionar.Clicando em Advanced teremos diversas opções de configuração. Na aba “Backup” podemos escolher qual o modo que nosso backup irá funcionar.
- Reversal incremental
- Esse modo é utilizado para injetar os backups incrementais no arquivo do backup full, dessa forma o último arquivo de backup será sempre um backup full com todas as alterações do dia.
- Incremental
- Nesse modo é criado o arquivo incremental com todas as modificações desde o último backup. É o mais utilizado e o que garante uma melhor performance de I/O.
Se necessário você pode escolher a opção “Create syntheticalfull backups periodcally” para que seja criado um backup periodicamente se for o seu caso.Um pouco mais embaixo você pode escolher um dia exato do mês para que um novo backup full seja criado, mas essa opção vai depender de como funciona sua rotina.
Para maiores detalhes dessas opções CLIQUE AQUI.
No meu exemplo, eu quero que seja criado um backup full toda última sexta-feira do mês e os demais backups serão todos incrementais.
Na aba “Maintenance” podemos definir que seja feito um “health check” periodicamente nos arquivos de backup.
Também podemos definir a manutenção dos arquivos de backup para efetuar a defragmentação, limpar dados obsoletos e compactar o arquivo do backup full.
Para maiores detalhes dessas opções CLIQUE AQUI.
No meu exemplo mantive as opções default.
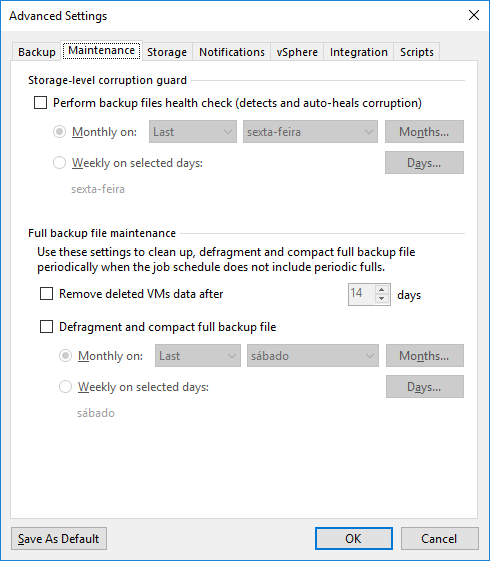
Na aba “Storage” podemos definir as opções de como o job vai trabalhar para ganharmos maior performance e redução do espaço em disco. Se você não tem certeza de qual utilizar, mantenha as opções padrão e acompanhe o job com o passar dos dias. Com isso você terá uma ideia de como o job está se comportando e poderá adequar da melhor forma. Lembre-se de qualquer alteração no level de compressão significa um maior uso de recursos do servidor do VEEAM.
Em “Storage optimization” podemos definir como o nosso repositório está conectado com o nosso VEEAM para saber como ele deve lidar com os dados. Cada opção tem vantagens e desvantagens.
Em “Encryption” podemos definir uma senha para criptografar os arquivos de backup.
Para maiores detalhes dessas opções CLIQUE AQUI.
No meu exemplo novamente mantive as opções default.
Na aba “Notifications” podemos configurar as notificações e eventos em caso de sucesso ou falha do job.
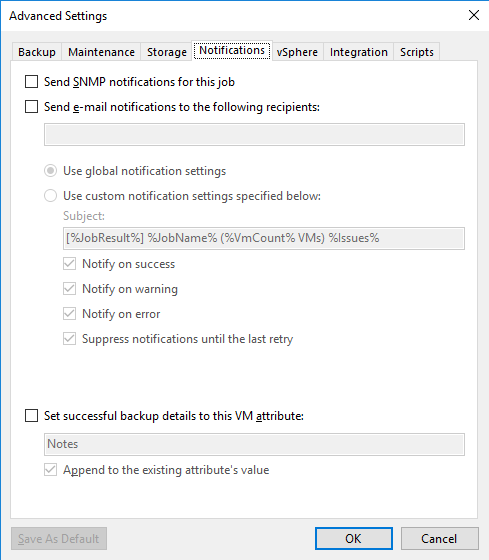
Na aba “vSphere” podemos definir algumas opções de como o job vai agir ao iniciar o processo do snapshot nas VMs do host. Marque a opção “Enable VMware Tools quiescence” se deseja que o snapshot seja gravado com a VM em estado consistente. Normalmente não vamos utilizar essa opção, apenas em caso de backup de VMs com aplicações que tem alto IO como SQL ou Exchange.
Em “Changed block tracking” mantenha as opções marcadas para o VEEAM utilize o CBT para criação de arquivos de backup incrementais. De forma simples, o CBT serve como ponteiro para o VEEAM saber a partir de onde ele deve começar um backup diferencial.
Para maiores detalhes dessas opções CLIQUE AQUI.
Para maiores detalhes sobre o CBT CLIQUE AQUI.
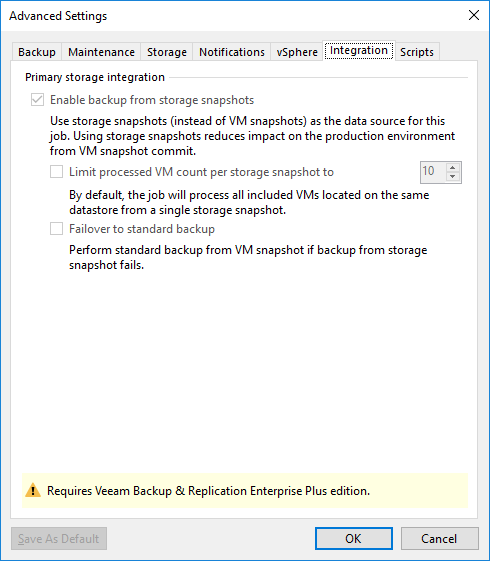
Na aba “Integration” podemos fazer com que o VEEAM use snapshots de storage ao invés dos snapshots das VMs, reduzindo significativamente o impacto no ambiente de produção. Entretanto, essa é uma feature disponível apenas na versão Enterprise.
Para maiores detalhes dessas opções CLIQUE AQUI.
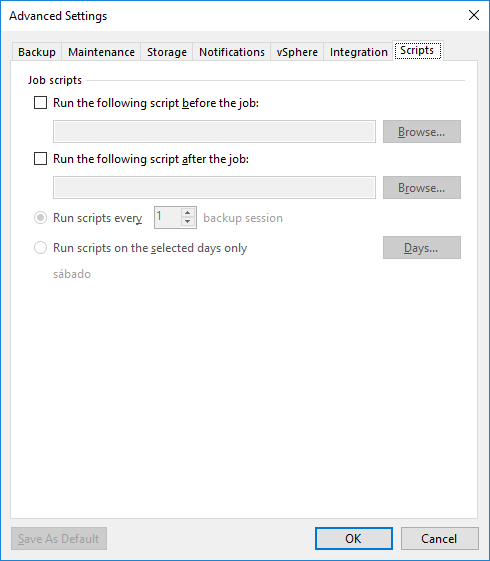
Na aba “Scripts” podemos definir scripts para que sejam executados antes ou depois que um job de backup rodar.
Após configurar todas as opções avançadas do job clique em “OK” e “Next”.
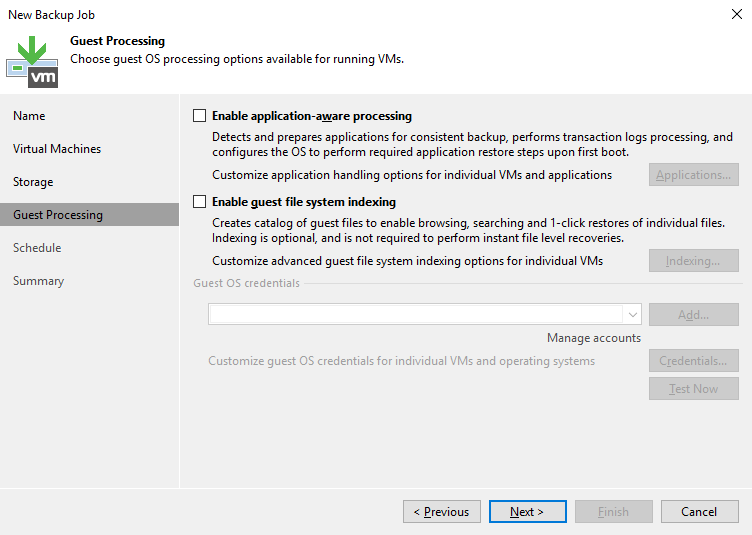
Em “Guest Processing” podemos escolher as opções para que o VEEAM avise o sistema operacional que será feito um backup na VM, dessa forma aplicações com o Exchange e o SQL poderão processar os logs, por exemplo. Para utilizar essa função devemos também definir uma credencial para o VEEAM ter acesso ao sistema operacional da VM.
Para maiores detalhes dessas opções CLIQUE AQUI.
Manterei todas as opções desmarcadas porque no meu caso não tenho nenhuma aplicação que necessite desse tipo de ação na VM. Clique em “Next” para prosseguir.
Em “Schedule” defina os dias e horários que deseja que seu job seja executado. Também é possível definir quantas vezes o job deve tentar em caso de falha e também podemos definir um horário para que o backup seja encerrado mesmo sem que tenha terminado para que não impacte horário de produção. Defina da forma que melhor se adeque ao seu ambiente e clique em “Apply”.
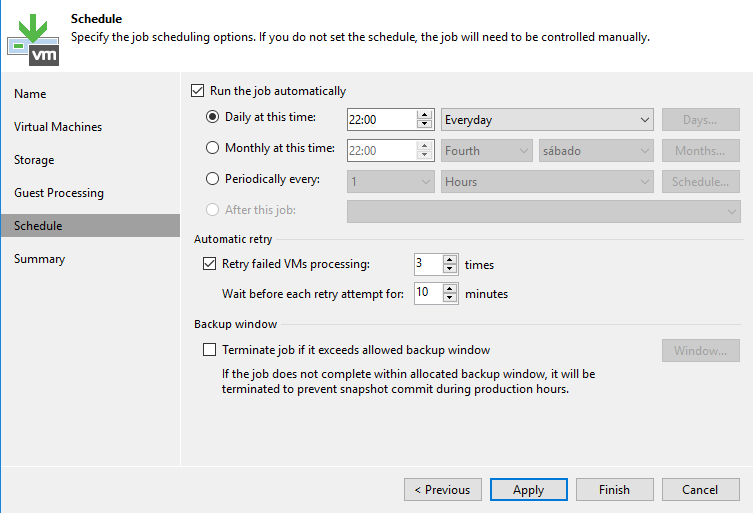
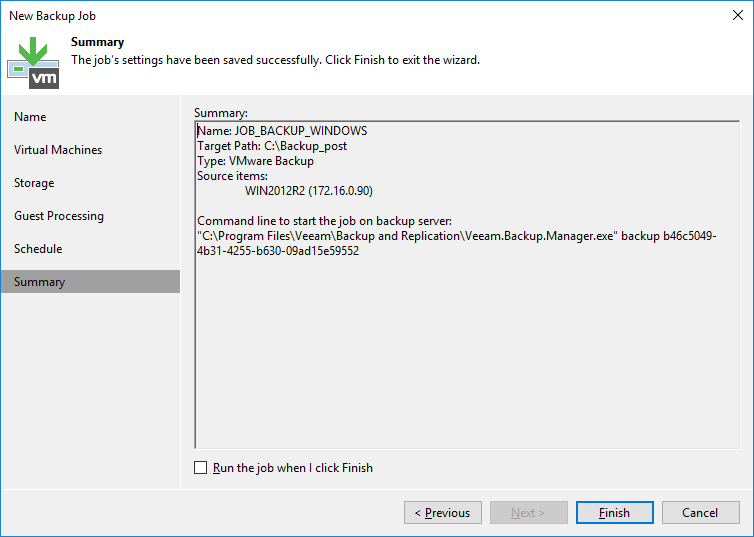
Revise as opções do job e clique em “Finish”.
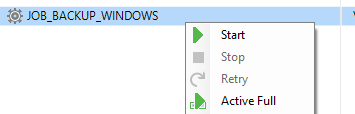
Agora iremos iniciar o job para criar o primeiro arquivo do backup full. Clique com o botão direito no job e clique em “Start”.
Você pode acompanhar do job clicando duas vezes nele.
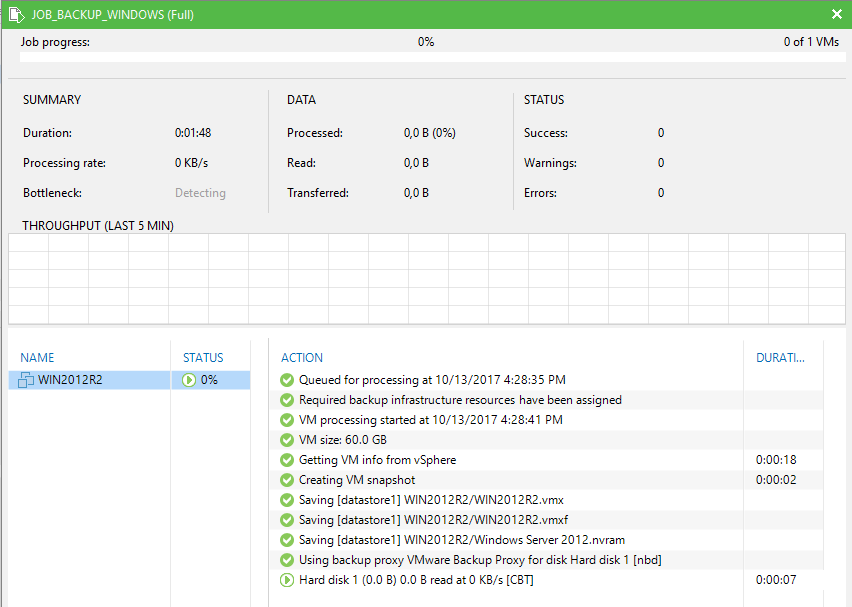
Após finalizar teremos o arquivo .VBK (FULL) criado em nosso repositório. Na próxima vez que o backup executar teremos um arquivo .VIB (INCREMENTAL) criado em nosso repositório referente apenas as modificações desde o último backup.

Com isso finalizamos a criação do job para backup!
No próximo artigo mostrarei as opções de como efetuar o restore e um exemplo de restauração de guest files no Windows.
Até breve!
Compartilhe!